
Стартовая страница курса Диагностика проблем производительности 1С: что конкретно тормозит систему
Если Вы впервые приступаете к изучению курса от проекта Курсы-по-1С.рф
Регистрация на сайте
Перейдите на страницу регистрации.
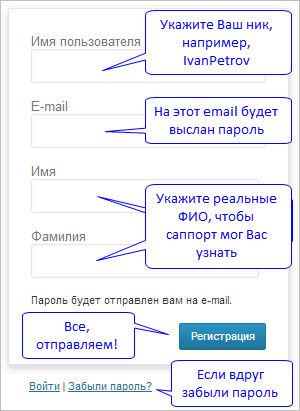
При регистрации нужно ввести следующие данные о себе:
- Ник (имя на сайте)
- Электронную почту
- Реальные Имя и Фамилию
Но по имени фиксируются обращения на саппорт, а на e-mail высылаются пароль и обновления.
В конце концов — Вы покупатель курса, нам приятнее писать «Доброго дня, Михаил», чем «Здравствуйте, слушатель № 4825»…
Пароль для входа на сайт придет Вам на указанную электронную почту, поэтому обязательно проверьте корректность e-mail.
Если Вы не получили письмо — проверьте папку «Спам» (чтобы гарантировано получать наши рассылки, добавьте наш электронный адрес support@kursy-po-1c.ru в адресную книгу).
Пароль позднее можно будет поменять в своем профиле.
После того, как Вы получили пароль — авторизуйтесь на сайте.
Начало обучения
Это курс свободного изучения:
- Без жесткого плана-графика
- Без практических заданий и отчетов по ним.
Таким образом, как только Вы готовы начать заниматься — активируйте токен, скачивайте материалы и приступайте к изучению.
Вопросы по курсу
Поддержка преподавателя доступна для старших версий этого курса.
По данному курсу принимаются только вопросы организационного плана.
Поддержка в Мастер-группе по старшим курсам дает возможность:
- Задать свои вопросы по курсу
- Изучить ответы на вопросы других участников
Чтобы Вы понимали, что мы разбираем в Мастер-группе, приведем несколько примеров.
Обязательно ознакомьтесь с разбором этих вопросов при изучении курса — это будет полезно.
Для обучения используйте БСП версии 2.2.5.36.
Ответы на вопросы по занятию 1 - APDEX
Вопрос 1
Почему в формуле расчета APDEX нет учета количества строк в документе? Разве корректно утверждать, что документ с одной строкой отработал 1 с. — это хороший показатель производительности, а документ с 500 строками отработал за 20 с. – это неудовлетворительно.
Если у вас разные требования к одной операции, то надо разделить эту операцию на несколько. Например, документ размером до 50 строк – это одна ключевая операция с целевым временем 3 сек, а от 50 до 100 строк – это другая ключевая операция с другим целевым временем.
![]()
Вопрос 2
Есть желание проверять АПДЕКС для операций, выполняющихся на клиенте. При этом хотелось бы получать информацию о том, с какой клиентской машины выполнилась операция. Насколько я понял функционал БСП и Сервисов, такой возможности нет. Как бы вы порекомендовали реализовать подобный функционал?
В сервисе APDEX есть дополнительное поле «Описание», куда вы можете писать любую информацию, в том числе и имя компьютера.
![]()
Вопрос 3
Мы ставим (включаем) у клиента подсистему производительности. Получаем значения Apdex. Допустим, по Apdex у клиента все довольно неплохо. А клиент жалуется на проблемы производительности («все медленно и плохо»). Что дальше делать: снимать счетчики оборудования? А если и они покажут, что все в пределах нормы? Т.е. когда Apdex показывает «плохие» значения и эти значения именно по тем точкам, на которые жалуются пользователи — понятно что делать (исправлять запросы, проблемы на блокировках и прочее). А вот в каком случае нужно смотреть параметры (счетчики) оборудования?
> Допустим, по Apdex у клиента все довольно неплохо. А клиент жалуется на проблемы производительности («все медленно и плохо»).
Это значит, что у вас целевое время установлено неправильно, оценка пользователей должна соответствовать апдексу. Либо второй вариант, замеры встроены неверно. Добейтесь того, что апдекс совпадал с оценкой пользователей.
> Что дальше делать: снимать счетчики оборудования? А если и они покажут, что все в пределах нормы?
Счетчики надо снимать надо в любом случае, так же как и рег. задания надо делать в любом случае.
![]()
Вопрос 4
Вопрос по регистру «Замеры времени». Первое выполнение ключевой операции занимает, к примеру, 25 секунд, а последующие — десятые доли секунды. Будет ли корректно потом обработано это в Apdex? Правильно ли я понимаю, что первый замер — это, по всей видимости, связано с отсутствием в кэше данных?
Да первый замер – это, скорее всего, кэш. Этот замер тоже будет участвовать в расчете Apdex, но чтобы Apdex был показательный, рекомендуется выполнить не менее 100 замеров. В этом случае это отклонение не будет сильно влиять на вычисления.
![]()
Вопрос 5
Если смотреть замеры APDEX по часам в течение дня и по дням в целом, то можно наблюдать ситуации, в которых в некоторые часы индекс падает до негативных оценок, а в целом оценка за день, тем не менее, удовлетворительна. Стоит ли обращать внимание на негативные показания apdex при оценке замеров за 1 час. Или все же стоит ориентироваться на дневную оценку?
Здесь стоит ориентироваться на мнение клиента. Возможно этот час для него как раз и является самым критичным. В этом случае конечно нужно обращать внимание именно на это время.
Кстати, если видна такая зависимость по времени, следует провести расследование, что в этот час делается. Возможно стартуют какие-то регламентные задания, бэкапы, дефрагментация диска, стартует антивирус на сервере или еще что-нибудь. Надо посмотреть на загрузку железа в этот период и т.д.
![]()
Вопрос 6
Стоит ли применять АПДЕКС и всякие замеры если база:
1) типовая файловая (например работает 1-10 пользователей)
2) типовая клиент-серверная.
То есть даст ли это какой-то эффект, ведь мы ничего оптимизировать не сможем, так как за нас 1С прооптимизировала код.
Максимум – это настроить во 2-м варианте СУБД и 1С-сервер. А в 1-м случае вообще даже не стоит и предлагать решить вопросы тормознутости клиентам? =)
В типовых конфигурациях Apdex уже встроен, вам остается его только включить. Это как минимум даст вам возможность оценить реальное положение дели увидеть, за какое время выполняются ключевые операции.
Оптимизация всегда подразумевает под собой модификацию кода, если хотите что-то оптимизировать то от этого никуда не деться. Без кода можно только настроить СУБД и выполнить там все рег. операции, но драматической разницы в скорости это не даст.
Что касается файловой базы, она изначально не рассчитана на параллельную работу. Если клиента не устраивает ее производительность, можно предложить ему переход на клиент-серверный вариант, это и есть решение проблем «тормознутости». Либо как вариант можно построить работу сотрудников так, чтобы они одновременно работали с разными типами документов.
![]()
Вопрос 7
В УПП 1.3.57.1 есть БСП оценки производительности, но проведение документов фиксируется только при ручном проведении документов. При групповой обработке — регистр сведений Замеры времени остается пустым, соответственно, данные не попадают в обработку Оценка производительности. Это правильно, или еще что-то надо включить?
Такое поведение, потому что код замера срабатывает только при нажатии на кнопку.
В вашем случае групповое перепроведение можно считать отдельной ключевой операцией, т.к. к ней предъявляются другие требования по времени, об этом говорилось в видеоуроке. Т.е. вам нужно мерить не сумму времен проведения документов, а общее время выполнения группового перепроведения.
![]()
Ответы на вопросы по занятию 2 - Мониторинг загруженности оборудования
Вопрос 1
Есть ли разница при выборе счетчика мониторинга процессора % загруженности процессора из раздела Процессор или Процесс или Сведения о процессоре? Или если не выбирать ядра или конкретные процессы, то они будут совпадать?
Счетчики в разделе Сведения о процессоре и Процессор одинаковы, счетчик в разделе Процесс имеет смысл, только если нужна детализация по процессу ОС (например, отследить, как нагружают процессор rphost-ы), если выбрать Total, то счетчик будет показывает какие-то нереальные значения выше 100 %.
![]()
Вопрос 2
Подскажите, вы говорите о том, что следует собирать информацию о производительности оборудования не только на виртуальной, но и на физической машине. Подойдет ли описанный вами способ мониторинга оборудования vmstat для esxi?
У EXSI есть свои инструменты для анализа загрузки оборудования. http://www.doublecloud.org/2010/12/vsphere-performance-counters-for-monitoring-esx-and-vcenter/
![]()
Вопрос 3
А в чем принципиальная разница в информативности показателей средняя очереди диска и текущая очереди диска в мониторе производительности?
Средняя длина очереди диска — это среднее общее количество запросов на чтение и на запись, которые были поставлены в очередь для соответствующего диска в течение интервала измерения.
Текущая длина очереди диска — это количество невыполненных запросов к диску во время сбора сведений о загруженности. Сюда включаются запросы, обслуживаемые во время проведения замера. Этот показатель представляет собой конкретное текущее значение и не является средним значением по некоторому интервалу времени.
Многошпиндельные дисковые устройства могут обрабатывать одновременно несколько запросов, остальные имеющиеся запросы будут ожидать обслуживания. Этот счетчик может отражать постоянные изменения длины очереди, показывая то большую, то малую ее длину, но если имеется перегрузка дискового устройства, то вероятно, что значение этого счетчика будет большим постоянно. Время задержки обработки запросов пропорционально длине этой очереди минус количество шпинделей дисковых устройств. Для хорошей производительности системы среднее значение этого счетчика не должно превышать двух.
![]()
Вопрос 4
Подскажите на практическом примере, что же значит показатель очереди к дискам. (Очередь к дискам «Не более 2*Кол-во дисков работающих парал-но»).
По факту RAID 10 (16 дисков), на физической машине два виртуальных сервера с ролью SQL Server и Сервер 1С. Запускаю perfmon на вирт. сервере с ролью SQL, очередь около 2, что это? Насколько понимаю, очередь к физическим дискам? И какой уровень опасный? Как посчитать ее на данном конкретном примере?
1. Если у вас используется виртуальная машина, то надо убедиться, что диск у вас подключен напрямую, т.е. виртуальный диск не используется.
2. Если у вас RAID 10 (16 дисков), то по факту при параллельной записи используются только 8 дисков, т.к. остальные 8 просто дублируют информацию, это значит, что для вас очередь может достигать 8*2=16. Подробнее можно почитать здесь: https://ru.wikipedia.org/wiki/RAID#RAID_10_.281.2B0.29
При этом надо помнить: прежде чем диагностировать загруженность оборудования, необходимо, чтобы показатель был превышен в течение длительного времени. Если у вас очередь 2, то диски справляются с нагрузкой.
![]()
Ответы на вопросы по занятию 3 - Расследование проблем производительности
Вопрос 1
Есть очень наболевший для меня вопрос.
Пример. Позавчера обнаружился в системе один (из многих) запрос, который выполняется довольно долго (выгрузка данных в другую систему). Запрос по регистру сведений, контактная информация с соединением ещё одной таблицы документа. Данных много, структура регистра не самая приятная, запрос относительно тяжелый и выполняется долго.
Когда он выполняется — пользователи начинают жаловаться, что 1С тормозит. Причем жалуются разные пользователи (выполняющие разные действия в системе). Во многом тормозит даже то, что с контактной информацией, казалось бы, даже не связано. Т.е. выполняется запрос на чтение информации из одной таблицы (регистр + документ), а при этом тормозит вся система (и чтение и запись).
Я могу предположить, что т.к. запрос тяжелый для сервера баз данных, то сервер баз данных для его выполнения настолько напрягается, что это сказывается на всём сервере. Такое может быть? Или же есть (могут быть) какие-то другие причины?
Помимо этого, также не редко возникают аналогичные ситуации. Начинаются жалобы: тормозит 1С. Давай смотреть в консоли, кто-то что-то запустил. Звоним, спрашиваем, а там какой-то отчет, например. Причем, условно говоря, отчет формируется по документу Расходная накладная, а тормоза проявляются при проведении Заказа покупателя, в котором нету ни чтения, ни записи информации о расходной.
Подскажите, пожалуйста, какие могут быть причины такого поведения системы?
Вам надо настроить сервис анализа долгих запросов или ЦУП и в первую очередь сбить пар, т.е. оптимизировать TOP найденных медленных запросов. Эти запросы у вас занимают ресурсы системы, в частности, скорее всего, дисковую подсистему.
>Я могу предположить, что т.к. запрос тяжелый для сервера баз данных, то сервер баз данных для его выполнения настолько напрягается, что это сказывается на всём сервере. Такое может быть? Или же есть (могут быть) какие-то другие причины?
Да, скорее всего так и есть. Запрос нужно либо оптимизировать, либо сократить объем собираемых данных, либо выполнять запрос в нерабочее время.
![]()
Вопрос 2
Использую сервис Анализ длительных запросов. Логи пишутся. Связь с веб-сервисом есть. Но если вызвать обработку Включение(обработка) тех.журнала — Обработать, то выдается сообщение, что Обработано файлов 0 и т.п., все по нулям. Что делаю не так?
И еще вопрос: в настройках указывается, что нужно писать план запроса, а в логах его — нет. Есть контекст, но нет плана запроса. Хотя в настройках ТЖ есть: query_b:property name=»planSQLText». Куда смотреть?
Сервис сам каждый час отправляет данные. Если вы хотите отправить данные раньше, тогда придется сервис сначала остановить, отправить данные и потом снова запустить. Если не остановить, то файл будет заблокирован, и сервис не сможет его прочитать. План должен быть, если он включен, то его не может не быть.
![]()
Вопрос 3
Если уже стоят облачные сервисы для одной базы, при настройке сервисов для другой базы необходимо указывать иной путь к файлу logcfg.xml? Просто столкнулся с ситуацией, когда захожу в сервис анализа ТЖ по одной регистрации и вижу там ошибки по тестовой базе (другая регистрация).
Если используется сервис анализа ошибок или сервис неоптимальных запросов, то они собирают данные со всех баз, которые расположены на данном сервере.
Если используется сервис анализа блокировок или взаимоблокировок, тогда для каждой исследуемой базы придется создавать отдельную базу сервиса. Путь к ТЖ может быть один, все равно они будут писать логи в разные каталоги.
![]()
Вопрос 4
На одном сервере стоит сервер баз данных MS SQL и три версии сервера 1С (8.1, 8.2 и 8.3). На сервере 1С 8.3 подключена конфигурация Управление торговлей 11.1.6.20, при работе с которой наблюдаются большие задержки практически при любом действии (открытие списка документов, форм документов и справочников). При этом базы на серверах 1С 8.1 и 8.2 работают без значительных задержек.
На что нужно обратить внимание для анализа проблем с производительностью? Возможно это связано с тем, что процесс sqlserv.exe (SQL Server 2005 9.00.5057.00) занимает менее 1Гб, при этом в настройках сервера указан максимально допустимый размер ОЗУ 18Гб. Из 32Гб занято 23Гб. Т.е. не удается заставить SQL-сервер брать памяти больше.
Не пытайтесь угадать решение, не проводя анализ. Чтобы понять, хватает ли памяти серверу MS SQL, используйте счетчик.
Кстати, у вас SQL надеюсь 64-разрядный? Чтобы понять, перегружено ли оборудование, используйте системный монитор.
Настройте сервис анализа запросов в первую очередь и соберите данные за 1 день. Посмотрите, какие запросы у вас попадут в выборку, если там будут системные запросы, тогда имеет смысл посмотреть в сторону железа. Сделайте сначала это.
Также имеет смысл проверить, будут ли замедления после перезагрузки службы сервера 1С. Кстати, некорректно сравнивать 8.2 и 8.3, если конфигурации и базы разные, сравнивать имеет смысл одну базу на разных версиях платформы, так что дело возможно не в 8.3, а в конфигурации.
![]()
Вопрос 5
Можно ли использовать облачный сервис анализа долгих запросов для СУБД Postgree SQL, установленной на ОС Linux?
Если сервер 1С на Windows, то можно, главное – настройку в сервисе с типом СУБД поставить, чтобы сервис знал, какой формат плана запроса.
![]()
Вопрос 6
Смотрю видео из модуля 3 «Анализ неоптимальных запросов с помощью ЦУП. Настройка». Вы там говорите, что включать опцию получения плана запроса не рекомендуется, если система высоконагружена.
За счет чего получается нагрузка? Если учесть, что вы говорили выше, то собрать статистику я могу в пик, а запустить её анализ, когда система «отдыхает». Так я и не понял, каким всё же образом и когда ЦУП нагружает систему?
<...> ответ хотелось бы услышать примерно следующий. В момент анализа статистики ЦУП нагружает сервер СУБД (который в свою очередь нагружает процессор и ест память) и сервер приложений (который отъедает память). Это как пример. Ну и почему получение плана может создавать проблемы?
Когда вы включаете сбор планов, то происходит следующее:
1. Серверу СУБД придется этот план формировать для передачи серверу 1С, и это по каждому запросу который попадает под фильтр, на это уходит время.
2. Серверу 1С приходится каждый из этих планов писать в лог ТЖ, а для больших запросов планы тоже большие, на это также уходит время.
Если вы установили фильтр по длительности, в который попадает мало запросов, тогда сбор планов можно смело включать, это не будет вызывать замедления. Но если не поставили фильтр на длительность запросов или поставили, но маленький, или вы включили анализ блокировок или дедлоков и для запросов поставили получение плана, тогда в ТЖ придется фиксировать каждый запрос, и для каждого из них нужно получать план, в том числе и для служебных запросов, и это может ощутимо нагрузить сервер 1С и СУБД, и логи также сильно увеличатся в размерах.
![]()
Ответы на вопросы по занятию 4 - Базовые причины неоптимальной работы запросов
Вопрос 1
Вопрос по ссылкам и представлениям. Если я пишу в консоли запрос типа «Выбрать ссылка из Справочник.Номенклатура», то в окне вижу наименование. По плану запроса видно, что наименование не выбирается. Кто, когда и как подменяет ссылку наименованием? Если это делает сервер 1С предприятия, то может случиться так, что он возьмет наименование из кэша, без обращения к базе?
У меня был отчет, который работал быстрее, если в запросе бралась только ссылка, без наименования (хотя 1С рекомендует наоборот). Правда, это было давно (на 8.1 или 8.0, точно не помню).
Наименование получается в момент вывода запроса на экран. Включите трассировку без фильтра по длительности и вы увидите, столько запросов к наименованию, сколько строк у вас будет выводиться на экран.
![]()
Вопрос 2
Допустим, есть регистр сведений с измерениями Из1, Из2, Из3, Из4.
1) Правильно ли я понял, что составной индекс по нескольким полям (например Из2 + Из3) средствами платформы сделать невозможно?
2) Есть запрос, выбирающий данные по этому регистру. В секции ГДЕ стоят условия по Из2 и Из4. Кластерный индекс здесь невозможно использовать (Нет 1 измерения + зазор). Добавить условия по Из1 и Из3 не позволяет логика запроса. Изменение измерений в конфигураторе приведёт к падению производительности в других запросах. Правильно ли я понимаю, что наиболее правильным вариантом будет отдельно проиндексировать Из2 и Из4, тогда будет использоваться не clustered index scan а index seek по Из2 и index seek по Из4?
1. Да вы все правильно поняли.
2. Да все верно. Но у вас будет 2 отдельных индекса, следовательно, будет использоваться только какой-то один из индексов + частичное сканирование. В данном случае можно либо поменять логику приложения, сделать еще один регистр, либо создать индекс средствами СУБД и следить, чтобы он не удалился из таблицы, если вдруг будет реструктуризация.
![]()
Вопрос 3
Имеется запрос:
ВЫБРАТЬ
ЦеныНоменклатурыСрезПоследних.Номенклатура,
ЦеныНоменклатурыСрезПоследних.ТипЦен
ИЗ РегистрСведений.ЦеныНоменклатуры.СрезПоследних(
,
Номенклатура В ИЕРАРХИИ (&Номенклатура)
И ТипЦен В ИЕРАРХИИ (&ТипыЦены)) КАК ЦеныНоменклатурыСрезПоследних
Измерения регистра: ТипЦен, Номенклатура, ХарактеристикаНоменклатуры.
План получается сложный с KEY LOOKUP в ведомой таблице с соединением с помощью оператора NESTED LOOPS. Ведущая таблица — индекс по полю номенклатура, ведомой таблицей является индекс того же регистра по периоду. В итоге имеется большое число выполнений, что сильно увеличивает стоимость запроса. Причем соединение используется, чтобы получить поля номенклатуры и характеристик. Почему бы не использовать для этого индекс по измерениям?
При текущем условии у вас может использовать или индекс по номенклатуре, или индекс по типу цены, составной индекс с условием «В» не получиться использовать. Как вариант можно сделать временную таблицу с возможными пересечениями Номенклатур и типов цен и использовать условие (номенклатура, типцены) В (Выбрать Номенклатура, ТипЦены из ВТ).
Только это подойдет в том случае, если номенклатур и типов цен не сильно много, иначе временная таблица будет гигантская.
![]()
Вопрос 4
Подскажите пожалуйста, при установке индексирования для измерения регистра накопления индекс создается только для таблицы движения? Для таблицы итогов возможен только кластерный индекс, создаваемый по умолчанию?
Индекс создается и для таблицы движений, и для таблицы итогов.
![]()
Вопрос 5
А почему бы не использовать например такое условие в параметрах:
ВЫБРАТЬ ПЕРВЫЕ 100
ТоварыНаСкладахОстатки.ХарактеристикаНоменклатуры,
ТоварыНаСкладахОстатки.Склад,
ТоварыНаСкладахОстатки.Номенклатура
ИЗ
РегистрНакопления.ТоварыНаСкладах.Остатки(
,
ХарактеристикаНоменклатуры = ЗНАЧЕНИЕ(Справочник.ХарактеристикиНоменклатуры.ПустаяСсылка)
И Склад = &Склад) КАК ТоварыНаСкладахОстатки
Тогда в плане получается поиск по индексу без промежутка:
336 1 |—Clustered Index Seek(OBJECT:([IMPL_KP_UPP_DEV_ANDREEV].[dbo].[_AccumRgT28554].
[_Accum28554_ByDims_TRRRRRN] AS [T2]), SEEK:([T2].
[_Period]=[@P1] AND [T2].[_Fld28549RRef]=[@P2] AND [T2].[_Fld28546RRef]=[@P3]) ORDERED FORWARD)
Это возможно только в том случае, если учет по характеристикам не используется, да и то, в этом случае проще было бы просто спустить характеристику в самый низ. Нам по условиям задачи надо выбрать данные независимо от значения характеристики, и неважно, заполнена она или нет, а ваш запрос выберет данные только с пустой характеристикой.
![]()
Вопрос 6
В базе есть рег. сведений «ЦеныНоменклатуры». Все измерения НЕ составные, ссылочные и ведущие. Записей в регистре 9,2 млн.
Измерения в порядке их следования: ТипЦен, Номенклатура, КодТовара (справочник, который по сути обозначает номер товара в партии), Характеристики (не используются).
Никак не удается попасть в индекс при получении среза последних, хотя известны все значения (ТипЦен, Номенклатура, КодТовара). Пробовал следующие варианты:
— передавал параметры в виртуальную таблицу отдельно для каждого измерения
— собирал все данные в одну таблицу и передавал в параметры в виде структуры «(ТипЦен,Номенклатура,КодТовара) В (ВЫБРАТЬ…)» — эта конструкция работает гораздо медленнее чем предыдущий вариант.
Сейчас остановился на таком варианте:
— собрал все данные в одну таблицу и соединил ее с физической таблицей с последующей обработкой — выполняется за доли секунды.
Столкнулся с такой же проблемой в регистре накопления — получаю остатки, заполнив все параметры, но плане запроса явно видно, что в индекс не попадает полностью (SEEK… WHERE…). В этом случае не получится использовать физическую таблицу…
Как попасть в индекс? Что я делаю не так?
Если используется 8.2, то там срезы на регистрах сведений работают плохо и могут сваливаться в скан из-за дурацкой архитектуры самого регистра на уровне таблицы. В 8.2 на больших таблицах надо делать срез собственным запросом и не использовать вирт. таблицу.
В 8.3, если вы получаете срез на дату, тогда можно включить итоги по регистру сведений, и вы будете точно попадать в индекс.
Насчет регистра накопления – при получении остатков там всегда будет частичный скан, но вы посмотрите, по какому полю этот скан идет. Как правило, это условие чтобы количество не равнялось нулю, т.е. по факту сканируется 1 или несколько строк, что несущественно. В курсе сказано, что Seek Where – это не всегда плохо, это плохо, только если сканируется большая часть таблицы.
![]()
Вопрос 7
Правильно ли я понимаю, что для временных таблиц возможен только один индекс?
Допустим, у меня 3 поля в ВТ А, Б и В. Допустим, запрос выстроен так, что где-то мне нужно соединение по А и Б, где-то по Б, затем по А, а где-то по Б и В. Как быть в этом случае? Создавать отдельную ВТ для каждого соединения?
Да, для врем. таблиц возможен только 1 индекс, если указать несколько полей, то индекс будет составной, например А+Б+В. Порядок в индексе зависит от того порядка, в котором вы выбирали поля на закладке «Индекс» в конструкторе запросов. Если временная таблица маленькая, то с индексами вообще можно не заморачиваться. Если она очень большая, тогда какими-то условиями придется пожертвовать, т.е. делайте состав индекса таким, чтобы он подходил для большего количества условий. Конечно, можно сделать копию временной таблицы с разными индексами, но думаю, что затраты на создание этих вт и индексов будут выше, чем выигрыш производительности.
![]()
Вопрос 8
Вот Вы рекомендуете не использовать соединения с подзапросами, а разбивать запрос на части и использовать временные таблицы. В случае MSSQL это выглядит логично и органично, а вот в случае, например, Oracle у меня уже возникают вопросы.
А именно, как 1С транслирует на запросы Oracle использование временных таблиц? Ведь в Oracle нет такого понятия временных таблиц, как это есть в MSSQL.
Некоторое время назад я читал статью Тома Кайта (известного специалиста по Oracle), где он отвечал на вопрос программиста, имевшего опыт в разработке на MSSQL, который хотел перейти на Oracle. Вопрос касался того, как же быть без временных таблиц в Oracle. Том Кайт ответил, что концепции в MSSQL и Oracle отличаются и что он настолько уверен в оптимизаторе Oracle, что рекомендует использовать его потенциал полностью, в том числе нагружая его подзапросами.
Как Вы относитесь к такому мнению? Заранее спасибо за ответ.
Я с Oracle мало работал, но точно знаю, что временные таблицы там есть, и они так же используются для оптимизации. http://www.interface.ru/home.asp?artId=22364
На оптимизатор надейся, да сам не плошай. Чем проще будет запрос, тем лучше. В MS SQL оптимизатор – это одна из самых дорогих и сложных компонент, очень много умных голов над ним работали, тем не менее, он тоже ошибается. По опыту использования Oracle для задач 1С могу сказать, что оптимизатор там ничуть не лучше, скорее даже наоборот. Постоянно возникали проблемы с теми запросами, которые в MS SQL работали отлично.
Не надо излишне усложнять жизнь оптимизатору, ему и так нелегко. Если вы видите, что запрос слишком перегружен, то лучше разбить его на несколько простых.
![]()
Вопрос 9
Есть ли какие-нибудь рекомендации по использованию условия «В». Если в запрос передаётся массив значений, и на поле накладывается условие «В» ? Если передается таблица значений и накладывается условие «В» по нескольким полям? Нужно ли предварительно выбирать данные из массива/таблицы значений во временную таблицу, индексировать и только потом соединять?
Также интересуют особенности работы с индексами оператора «В ИЕРАРХИИ».
Если использовать условие: Поле1 В (&Список), то индекс будет использоваться.
Если использовать условие: Поле1 В (&Список1) И Поле2 В (&Список2) — то для 1-го поля индекс будет использоваться, а вот для второго уже нет, т.е. будет Seek Where – частичный скан индекса.
В этом случае лучше сделать врем. таблицу, положить туда значения из списков и написать (Поле1, Поле2) В (Выбрать Поле1, Поле2 ИЗ ВТ) – тогда индекс может быть использован. В ИЕРАРХИИ надо стараться не использовать, лучше предварительно собрать список элементов из этой иерархии во врем таблицу, а потом в основном запросе написать: Или Поле1 В (Выбрать Поле1 ИЗ ВТ_ЭлементыИЗИерархии)
Или сделать внутреннее соединение с врем. таблицей: Таб1 Внутреннее соединение ВТ_ЭлементыИЗИерархии ПО Таб1.Поле1= ВТ_ЭлементыИЗИерархии.Поле1
![]()
 К сожалению, у Вас недостаточно прав для дальнейшего просмотра.
К сожалению, у Вас недостаточно прав для дальнейшего просмотра.
Если Вы приобрели курс, но еще не активировали токен — пожалуйста, активируйте доступ по инструкциям, высланным на Ваш email после покупки.
Если Вы не залогинены на сайте — залогиньтесь, вернитесь на эту страницу и обновите ее.
Если Вы залогинены, у Вас активирован токен доступа, но Вы все равно видите эту запись — напишите нам на e-mail поддержки.