
Рано или поздно вы столкнетесь с проблемой производительности системы. Например, в ситуации, когда доработки системы тестируются на какой-то выборке данных – но это всего лишь 5 — 10 документов или элементов справочника. Конечно, создавать вручную сотни объектов для глобальной проверки никто не будет. И именно в этот момент “закладывается” бомба замедленного действия.
Самое печальное, что внедренцы реально не могут предусмотреть такое поведение системы, так как на небольшой выборке данных система ведет себя отлично.
Или вот реальный кейс из нашей практики — в одной из версий типовой 1С: Розница в запросе выборки не стоял отбор при сохранении Чека ККМ. И документ проводился меньше секунды, а спустя время стал проводится по 2-3 минуты. И самое печальное то, что использовался APDEX, проводились замеры, и история показала плавный рост, в месяц на 0.1 секунду. Человеку такое поведение заметить нереально.
Тут возникает вопрос: как исключить такие ситуации? Особенно, если у нас уже есть контур и есть тесты.
В этой статье мы рассмотрим:
- Механику создания тестовой базы.
- Способ генерации десятков тысяч элементов справочников и документов буквально несколькими строками фича-файла.
- Способы выявления потери производительности без участия программиста.
С чего начинаются тесты
Все, кто так или иначе касался тестирования, знают, что тесты в 99% случаев оперируют данными. Даже дымовые и юнит тесты нередко зависят от данных системы, например, от тех же функциональных опций.
А если мы проводим сценарные тесты, то однозначно выполняем различные операции над данными в базе:
- создаем
- читаем
- проверяем
- модифицируем.
Шаблонные базы может позволить себе только очень большая компания, как же быть остальным?
Некоторое время назад мы отдали разработчикам Vanessa Automation механизм, который позволяет генерировать данные на основе реальных данных системы по зависимостям и потом загружать эти данные обычными шагами в сценарии в Vanessa Automation.
Суть этого механизма проста и интересна. Представим, что нам поставили задачу написать наш первый тест. И это должен быть тест на покрытие критического функционала, так как, если у пользователей стабильно “падает” РМК, и каждое утро из магазинов нам звонят с проблемами, то в таком случае писать тесты на проверку механизма взаиморасчетов было бы странно.
Когда нам ставят такого рода задачу, первое, что приходит в голову — взять копию реальной базы, обрезать данные, оставить только нужное и проводить в ней тесты, каждый раз обновляя конфигурацию. И вроде это неплохой вариант. Но самое страшное начинается потом.
Детально описывать, почему это неправильно, в этой статье не будем, затронем только пару моментов:
- Реальные данные системы имеют свойство меняться. И если изначально в сценарии теста вы привязались к тому, что Партнер1 имеет только одно соглашение, а теперь у него 2 соглашения, или пользователь переименовал номенклатуру, к которой мы обращаемся, то тесты начинают падать. Падать из-за того, что изменились данные в системе, а не из-за ошибок программиста или тестировщика.
Можно откатить конфигурацию и посмотреть, что в ней было раньше, но проблема в том, что бекапа шаблонной базы может и не быть. Вы можете взять версию конфигурации из хранилища или гита трехлетней давности, но тесты запустить на ней вы не сможете. - Что касается подготовки тестовых данных, то в идеальной ситуации программисты не должны работать с реальными данными, особенно если они работают на аутсорсе. Когда к вам вышел новый сотрудник (ну или вы решили “одолжить” программиста с другого проекта), то в этих случаях программисту ничего не скажет наименование товара “Кирпич”, “Веревка”, “Молоко”. Потому что, когда программист пишет код, его интересует не название товара/клиента/договора, а его содержание и свойства. Согласитесь, что если эти товары переименовать в “Товар с учетом в разных единицах”, “Товар с характеристикой”, “Товар с объемом и весом”, “Товар с двумя видами цен”, “Товар 1 аналог Товар 2”, “Товар 2 аналог Товар 1”, “Контрагент с двумя договорами”, “Партнер с один соглашением” и т.д. — то работать с таким набором данных станет намного проще и понятней.
- Есть еще много примеров, почему организовывать данные именно так — это удобно, особенно, когда разработка мигрирует в git, и применяются методики GitHub flow и прочие. В этом случае шаблонные базы становятся просто якорем.
Вернемся к нашей теме — нам нужно подготовить тестовую базу данных. Давайте разберемся, как подготовить ее правильно, а “правильность” мы оценим по следующим критериям:
- Поддерживать изменения структур метаданных легко.
- Можно быстро провести анализ изменения метаданных (добавили / удалили реквизит или целый справочник).
- БАнализировать необходимую и достаточную структуру данных для теста легко. Например, если для этого теста нам не нужен вес товара, то в тесте его и не должно быть.
- Можно оперативно генерировать тестовую базу на основе любой конфигурации разработчика.
- Легко встроить этот подход в будущий CI контур.
Вывод: взяв реальную базу и обрезав лишние данные или взяв базу, где мы создадим тестовые данные сами, мы не попадем ни в один из этих пунктов.
Создаем тестовую базу
Как тогда сделать так, чтобы было просто и удобно? Ранее использовался подход, когда можно было сгенерировать MXL-файлы, которые создавались отдельно и потом загружались в базу, генерируя таким образом необходимый набор данных.
И это было круто, только абсолютно нечитабельно, а для актуализации данных вам приходилось все загрузить в пустую базу, изменить, а потом снова выгрузить и т.д.
Мы взяли эту идею за основу и кое-что доработали. Результат рассмотрим ниже.
Скачиваем Vanessa Automation, идем в специальную опцию генерации данных и делаем это в реальной базе данных. Не прямо в проде, хотя можно и в проде, а главное, что мы берем реальные данные конкретного предприятия.
Рассмотрим следующую задачу: надо написать тест на создание и проведение заказа клиента в демо базе УТ11. Мои действия:
- Я открываю VA в демо базе УТ 11, и открываю генератор тестовых данных:
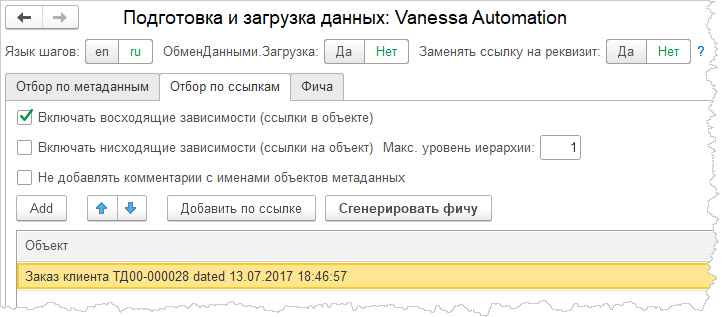
- Выбираю там один документ заказа, жму “Сгенерировать фичу” и получаю вот такой результат:
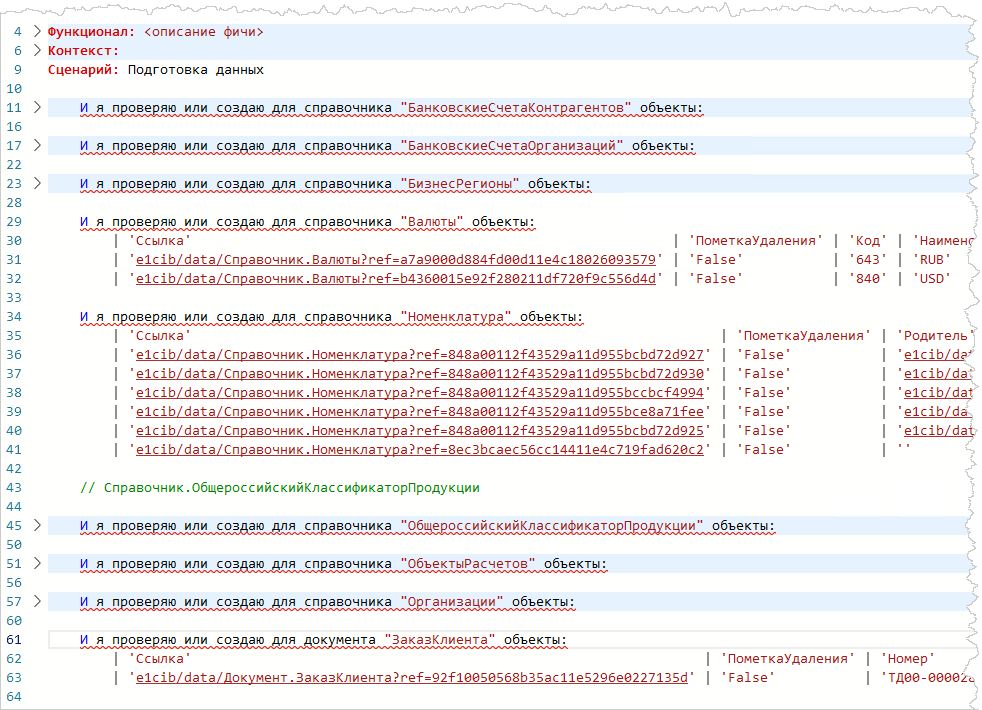
- Обрабатываю немного, а именно — удаляю то, что мне не нужно тут для тестов, например, адреса складов или другие данные, которые могли подтянуться.
- Обрабатываю заказ так, чтобы номер заказа, дата и т.д. не дублировались.
- Проверяю непосредственно в этой базе мой сценарий создания документа и проведения. Ведь я не привязан к номерам и прочим атрибутам. Поэтому я могу создать хоть десяток таких документов во время теста.
- Беру пустую базу УТ11 и выполняю в ней тест. Тест 100% упадет, так как в базе не будет важных данных, которые нужны для нормальной работы системы, например, настроенные учетные политики организаций или включенные необходимые функциональные опции.
- В демо базе я генерирую нужные мне данные (по пункту 6), и переношу в пустую базу, проверяя — ничего ли я не упустил. И когда все станет ок, я еще раз возьму пустую базу и удостоверюсь, что все грузится корректно.
- Доработаю свой сценарий теста: переименую партнеров, товары и прочее, ведь для этого мне достаточно просто в тексте задать переименование, что легко сделать через поиск/замену, а так как везде использованы ссылки, то меняться будут только нужные параметры.
- Потом вынесу всю подготовку данных в экспортный шаг и начну писать сам сценарий теста для документа заказа. Благо, что все цифры есть, нужные поля есть, можно просто скопировать и немного поправить.
- Все.
И теперь, чтобы протестировать документ реализации товаров, я могу просто использовать шаги этого же теста. Только для теста реализации, если это отдельный тег, я буду дополнительно подгружать также и заказ клиента.
Объемы данных
Когда мы разобрались с тем, как генерировать данные для теста, и поняли, что это очень просто сделать, задумаемся — а почему бы не проверить еще пару кейсов?
Например, я, как QA инженер, не могу проверить, сколько по времени будет открываться форма подбора товаров при условии, если в справочнике с номенклатурой заведено 100 000 товаров, так как у меня в тестовой базе нет такого объема данных.
Или насколько быстро будет открываться документ на 10 000 строк? Или сколько по времени будет проводиться документ Чек ККМ, если в системе этих чеков десятки тысяч?
Первый вопрос который приходит в голову — “а надо ли мне это вообще?” Или “а почему этого не сделает программист?” Оставим за скобками эти вопросы.
Мы не раз сталкивались с обновлениями типовых баз, где при проведении документа в запросе идет выборка из таблицы этого документа. Так вот в этом запросе должен был быть отбор по ссылке этого документа, но его там не было. И получалось, что пока в базе документов 10 — все работает быстро, а когда документов около 10 000 — все работает медленно. А так как эти 10 000 документов появились не сразу, а в течение года, то каждый день скорость проведения документа падала на 0.1 секунду, пока не случилось так, что документ стал проводиться почти минуту. И на это никто не жаловался! Так как деградация была настолько плавной, что люди успевали к этому привыкнуть, и заметили только тогда, когда включили APDEX.
Так вот, как можно помочь программисту оптимизировать код? Правильно — указать ему на ошибку. Других вариантов не много :)
А как QA может указать на ошибку? Код-то он писать не будет. На самом деле все просто — ему и не надо писать код.
Можно всего лишь написать вот такой тест:
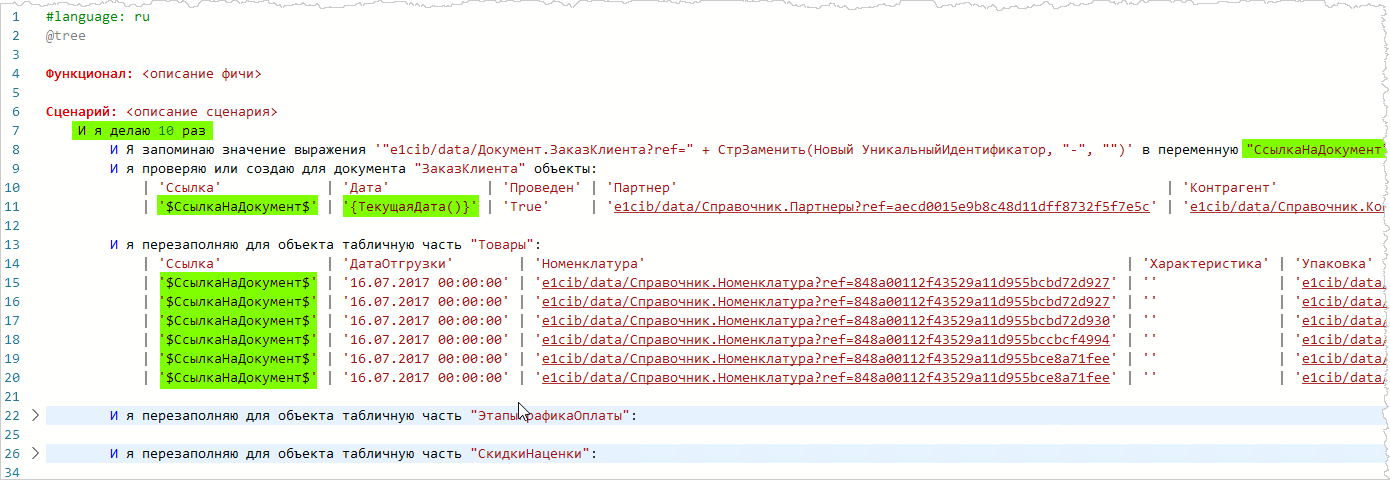
(нажмите, чтобы увеличить картинку)
Такой тест сгенерирует вам нужный объем данных в базе. А Allure отчет покажет вам общий тренд прохождения тестов. Этот тест отличается только двумя моментами: в 7-ой строке мы добавили цикл, в 8-ой строке — переменную, которую мы применяем ниже в сценарии для указания ссылки на документ.
И тогда, если программист где-то забыл поставить условие — вы это сразу заметите, так как тесты начнут проходить существенно дольше! Но на самом деле это не всегда будет означать, что программист написал “кривой” код. Возможно, он работает по “кривому” ТЗ. И в этом случае QA инженер сможет предупредить руководителя: если вот эта задача попадет в прод в таком виде — база “встанет”.
Подведем итог
Да, нельзя сказать, что проведение тестов влияет на производительность в чистом виде. Но такой простой подход, когда вы в три строки можете сгенерировать тысячи товаров или документов и проверить быстродействие функционала, позволяет оценить вам, нужно ли дальше “копать” в эту сторону, и насколько снизится производительность в короткий срок. Такие тесты рекомендуется выносить в отдельный тег и запускать периодически, вне основных потоков тестирования.
И самое главное — для реализации такой проверки не нужен программист.